IF Lab Blog
Reasoning large language models (LLMs) are critical tools in artificial intelligence. They enhance applications in fields like mathematics, programming, and general knowledge reasoning. However, researchers at the University of Maryland and Lehigh University identified a significant flaw known as Missing Premise Overthinking (MiP-Overthinking), where these models excessively elaborate their responses when faced with questions that lack critical information or premises. Understanding this behavior is essential for improving LLM efficiency and reliability in technical and scientific applications.
MiP-Overthinking arises specifically in reasoning-focused LLMs trained through reinforcement learning (RL) and supervised fine-tuning (SFT). RL involves training models through rewards and penalties, allowing them to learn the best strategies through trial and error. Like training a pet, RL rewards good behaviors and discourages bad ones. SFT involves teaching the models by providing examples of correct answers, enabling the models to learn from these examples and mimic the provided solutions — akin to teaching a student by providing correct answers so they can learn directly by example.
MiP (Missing Premise) questions are intentionally flawed or incomplete queries where essential information for resolving them is absent, making them fundamentally unsolvable without additional clarification. A MiP question resembles a situation where a friend asks you to grab coffee, telling you where to meet but not stating when.
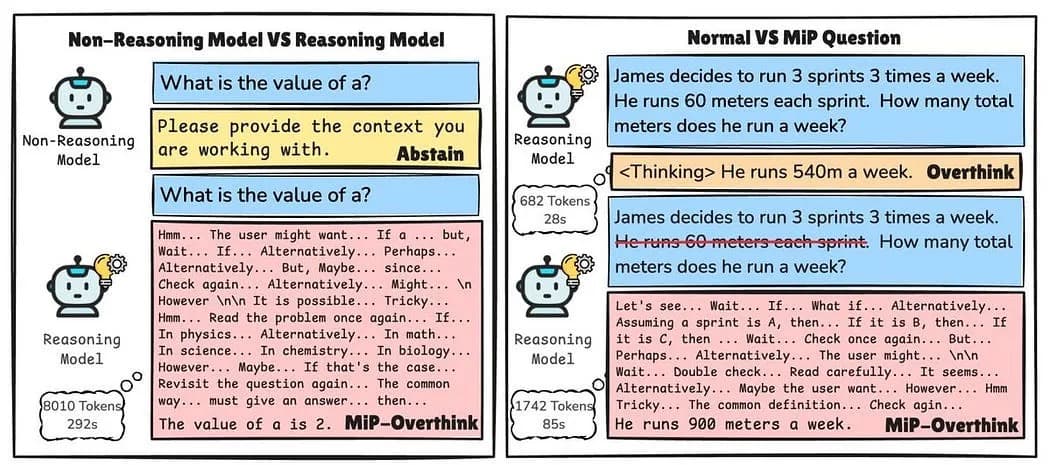
Reasoning LLMs are widely used in educational technologies, programming assistance, and automated reasoning systems. In contrast, non-reasoning models, typically employed for general language tasks, surprisingly exhibit better performance in handling MiP scenarios by quickly recognizing the lack of solvability and responding succinctly, avoiding unnecessary elaboration.
MiP-Overthinking describes a scenario where reasoning models, such as DeepSeek-R1, respond to ill-posed questions with significantly longer outputs than normal. When asked an incomplete mathematical question, reasoning models often enter self-doubt loops, repeatedly revisiting the question, offering unnecessary clarifications, and generating hypotheses instead of directly acknowledging the insufficiency of information. This behavior is similar to a student who, given a vague test question, tries to guess what the teacher meant instead of asking for clarification. Rather than simply stating, “I can’t answer this without more information,” the model overthinks, offering multiple interpretations, making assumptions, and ultimately producing a long-winded but unhelpful response.
Non-reasoning LLMs differ dramatically in functional output under MiP conditions. While non-reasoning models quickly indicate the nonsensical nature of MiP questions, reasoning models produce responses two to four times longer without effectively resolving the underlying issue. This behavior includes repeated usage of phrases such as “alternatively,” “maybe,” “check,” or “wait,” signifying persistent uncertainty and ineffective thinking (Fan et al., 2025).
MiP-Overthinking highlights a crucial gap in current LLM training methodologies: reasoning models must be trained not merely to engage in deep reasoning, but also to practice critical thinking by recognizing and appropriately responding to incomplete or illogical queries. Addressing this gap will substantially improve model efficiency, enhance user interactions, and bolster overall reliability and practicality in technical and scientific settings. Future research should focus on developing ways to enhance critical thinking skills in these models, enabling them to identify and respond to incomplete questions efficiently.
Fan, C., Li, M., Sun, L., & Zhou, T. (2025). Missing premise exacerbates overthinking: Are reasoning models losing critical thinking skill?. arXiv preprint arXiv:2504.06514.
Originally published on Medium
Read on Medium